一、什么是swap交换分区?
定义:Swap space交换空间,是虚拟内存的表现形式。系统为了应付一些需要大量内存的应用,而将磁盘上的空间做内存使用,当物理内存不够用时,将其中一些暂时不需要的数据交换到交换空间,也叫交换文件或页面文件中。

理解:我们知道Linux内核为了提高读写效率与速度,会将文件在内存中进行缓存,这部分内存就是Cache Memory(缓存内存),常用的就是buffer cache和page cache。即使你的程序运行结束后,Cache Memory也不会自动释放。
这就会导致你在Linux系统中程序频繁读写文件后,你会发现可用物理内存变少。当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到Swap空间中,等到那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。这样,系统总是在物理内存不够时,才进行Swap交换。
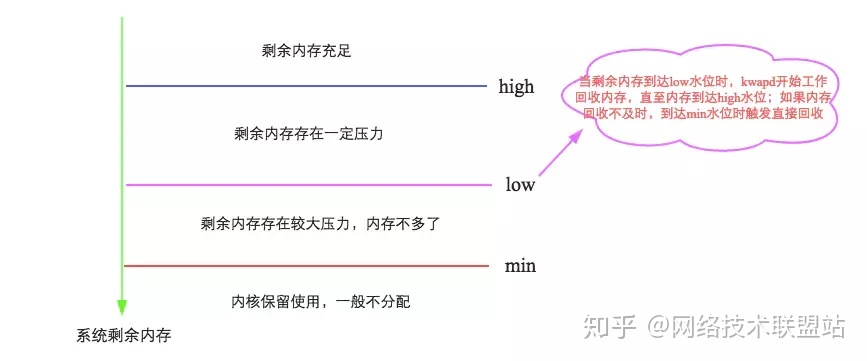
二、swap文件创建规则
参照oracle官方文档设定的标准应这样配置:
4G以内的物理内存,SWAP 设置为内存的2倍。
4-8G的物理内存,SWAP 等于内存大小。
8-64G 的物理内存,SWAP 设置为8G。
64-256G物理内存,SWAP 设置为16G。三、创建swap文件
1、安装操作系统分区时需创建swap分区。
2、安装操作系统时没有创建swap分区,需手动创建。
(1)查看内存情况
如果swap行为0,需要创建swap空间。
(2)创建swap分区
dd if=/dev/zero of=/tmp/swapfile bs=1024 count=8192000- if=/dev/zero:输入/dev/zero文件。/dev/zero主要的用处是用来创建一个指定长度用于初始化的空文件,就像临时交换文件。
- of=/tmp/swapfile:输出至/tmp/swapfile文件
- bs=1024:定义块大小为1024bytes,默认单位为bytes。
- count=8192000:总数大小8192000个bs即8192000kb,换算后得8G。
(3) 指定分区类型为swap
mkswap /tmp/swapfile(4)设置swap分区有效
swapon /tmp/swapfile(5)设置扩展的swap分区为自动挂载
Vim /etc/fstab添加自动挂载分区命令
/tmp/swapfile swap swap defaults 0 0(6)测试添加情况
Free -m四、扩展swap文件
程序运行时频频因为内存过小问题自动自杀,可手动扩展swap大小。 扩展方式: 1、先将swap关闭。Swapoff -a
2、安装三的步骤重新分配swap文件,重新加载swap分区。
五、swappiness参数
Swappiness是关于swap使用率的参数,swappiness的值越大,表示越积极使用swap分区,越小表示越积极使用物理内存。默认值swappiness=60。
当swap使用率配置过大影响到了磁盘使用,可以将此值适当减小直至配置为0。当磁盘空间io空闲较大,物理内存负载较高时可以将此值逐渐增大直至100。
1、临时调整Swappiness参数
sudo sysctl vm.swappiness = 100
cat /proc/sys/vm/swappiness2、永久调整Swappiness参数
sudo vim /etc/sysctl.conf修改
vm.swappiness=10然后执行命令:
sudo sysctl -pLinux将其物理RAM(随机存取存储器)划分为称为页面的内存块。交换是将一页内存复制到硬盘上的预配置空间(称为交换空间)以释放该内存页面的过程。物理内存和交换空间的组合大小是可用的虚拟内存量。
交换是必要的,原因有两个。首先,当系统需要的内存大于物理上可用的内存时,内核会交换较少使用的页面,并为需要内存的当前应用程序(进程)提供内存。其次,应用程序在其启动阶段使用的大量页面可能仅用于初始化,然后再也不会再使用。系统可以换出这些页面并释放内存用于其他应用程序甚至磁盘缓存。
但是,交换确实有缺点。与内存相比,磁盘速度非常慢。内存速度可以以纳秒为单位测量,而磁盘以毫秒为单位进行测量,因此访问磁盘的速度比访问物理内存要慢几万倍。发生的交换越多,系统就越慢。有时,在页面被换出然后很快交换然后再次换出等等时会发生过度交换或颠簸。在这种情况下,系统正在努力寻找可用内存并保持应用程序同时运行。在这种情况下,只添加更多RAM将有所帮助。
Linux有两种形式的交换空间:交换分区和交换文件。交换分区是硬盘的独立部分,仅用于交换; 没有其他文件可以驻留在那里。交换文件是文件系统中的一个特殊文件,位于系统和数据文件中。
要查看您拥有的交换空间,请使用命令swapon -s。输出看起来像这样:
文件名类型大小使用优先级
/dev/sda5 partition 859436 0 -1每行列出系统使用的单独交换空间。这里,’Type’字段表示这个交换空间是一个分区而不是一个文件,从’Filename’我们看到它在磁盘sda5上。’Size’以千字节为单位,’Used’字段告诉我们使用了多少千字节的交换空间(在本例中为none)。’优先级’告诉Linux首先使用哪个交换空间。关于Linux交换子系统的一个好处是,如果你安装两个(或更多)交换空间(最好是在两个不同的设备上)具有相同的优先级,Linux将交换它们之间的交换活动,这可以大大提高交换性能。
要向系统添加额外的交换分区,首先需要准备它。第一步是确保将分区标记为交换分区,第二步是制作交换文件系统。要检查分区是否标记为swap,请以root身份运行:
fdisk -l /dev/hdb将/dev/hdb替换为系统上具有交换分区的硬盘设备。您应该看到如下所示的输出:
设备启动开始结束块ID系统
/dev/hdb1 2328 2434 859446 82 Linux swap /Solaris如果分区未标记为交换,则需要通过运行fdisk并使用“t”菜单选项来更改它。使用分区时要小心 – 您不希望错误地删除重要分区,或者将系统分区的ID更改为错误交换。交换分区上的所有数据都将丢失,因此请仔细检查您所做的每项更改。另请注意,Solaris为其分区使用与Linux交换空间相同的ID,因此请注意不要错误地终止Solaris分区。
将分区标记为swap后,需要使用mkswap(make swap)命令以root身份进行准备:
mkswap /dev/hdb1如果您没有看到任何错误,则可以使用交换空间。要立即激活它,请键入:
swapon /dev/hdb1您可以通过运行swapon -s来验证它是否正在使用。要在引导时自动挂载交换空间,必须在/ etc/fstab文件中添加一个条目,该文件包含需要在引导时挂载的文件系统和交换空间的列表。每行的格式是:
由于交换空间是一种特殊类型的文件系统,因此许多参数不适用。对于交换空间,请添加:
/dev/hdb1 none swap sw 0 0其中/dev/hdb1是交换分区。它没有特定的挂载点,因此没有。它的类型为swap,选项为sw,最后两个参数未使用,因此输入为0。
要检查交换空间是否自动挂载而不必重新启动,可以运行swapoff -a命令(关闭所有交换空间),然后执行swapon -a(挂载/ etc / fstab文件中列出的所有交换空间) )然后用swapon -s检查它。
交换文件
除交换分区外,Linux还支持交换文件,您可以以类似于交换分区的方式创建,准备和装载。交换文件的优点是您不需要查找空分区或重新分区磁盘以添加额外的交换空间。
要创建交换文件,请使用dd命令创建空文件。要创建1GB文件,请键入:
dd if=/dev/zero of=/swapfile bs=1024 count=8192000- if=/dev/zero:输入/dev/zero文件。/dev/zero主要的用处是用来创建一个指定长度用于初始化的空文件,就像临时交换文件。
- of=/swapfile:输出至//swapfile文件
- bs=1024:定义块大小为1024bytes,默认单位为bytes。
- count=8192000:总数大小8192000个bs即8192000kb,换算后得8G。
/swapfile是交换文件的名称,计数8192000kb是以千字节为单位的大小(即8GB)。
使用mkswap准备交换文件就像分区一样,但这次使用交换文件的名称:
mkswap /swapfile同样,使用swapon命令安装它:swapon / swapfile。
交换文件的/etc/fstab条目如下所示:
/swapfile swap swap defaults 0 0我的交换空间应该有多大?
可以在没有交换空间的情况下运行Linux系统,如果你有大量的内存,系统将运行良好 – 但是如果你的物理内存耗尽,那么系统将崩溃,因为它没有别的东西可以do,所以建议有一个交换空间,特别是因为磁盘空间相对便宜。
关键问题是多少钱?较旧版本的Unix类型操作系统(例如Sun OS和Ultrix)要求交换空间是物理内存的两到三倍。现代实现(例如Linux)不需要那么多,但是如果你配置它们就可以使用它。经验法则如下:1)对于桌面系统,使用双系统内存的交换空间,因为它将允许您运行大量应用程序(其中许多应用程序可能空闲且易于交换),更多RAM可用于活动应用程序; 2)对于服务器,可用的交换量较小(比如物理内存的一半),这样您在需要时可以灵活地进行交换,但监控所使用的交换空间量并在必要时升级RAM; 3)对于较旧的台式机(仅说128MB),
Linux 2.6内核添加了一个名为swappiness的新内核参数,让管理员可以调整Linux交换的方式。它是一个从0到100的数字。本质上,较高的值会导致更多页面被交换,较低的值会导致更多的应用程序保留在内存中,即使它们处于空闲状态。内核维护者安德鲁莫顿说他运行他的桌面机器的吞吐量为100,说明“我的观点是减少内核交换东西的倾向是错误的。你真的不希望数百兆字节的BloatyApp不受影响内存在机器中浮动。在磁盘上取出它,使用内存来获取有用的东西。“
Morton的想法的一个缺点是,如果内存换得太快,那么应用程序响应时间会下降,因为当单击应用程序的窗口时,系统必须将应用程序交换回内存,这会让它感觉很慢。
swappiness的默认值为60.您可以通过键入root来临时更改它(直到下次重新引导):
echo 50 >/proc/sys/vm/swappiness如果要永久更改它,则需要更改/etc/sysctl.conf文件中的vm.swappiness参数。
结论
管理交换空间是系统管理的一个重要方面。通过良好的规划和正确使用交换可以提供许多好处。不要害怕尝试,并始终监控您的系统,以确保您获得所需的结果。
Better Linux Disk Caching & Performance with vm.dirty_ratio & vm.dirty_background_ratio
Bob PlankersDecember 22, 2013
Best Practices, Cloud, System Administration, Virtualization
This is post #16 in my December 2013 series about Linux Virtual Machine Performance Tuning. For more, please see the tag “Linux VM Performance Tuning.”
In previous posts on vm.swappiness and using RAM disks we talked about how the memory on a Linux guest is used for the OS itself (the kernel, buffers, etc.), applications, and also for file cache. File caching is an important performance improvement, and read caching is a clear win in most cases, balanced against applications using the RAM directly. Write caching is trickier. The Linux kernel stages disk writes into cache, and over time asynchronously flushes them to disk. This has a nice effect of speeding disk I/O but it is risky. When data isn’t written to disk there is an increased chance of losing it.
There is also the chance that a lot of I/O will overwhelm the cache, too. Ever written a lot of data to disk all at once, and seen large pauses on the system while it tries to deal with all that data? Those pauses are a result of the cache deciding that there’s too much data to be written asynchronously (as a non-blocking background operation, letting the application process continue), and switches to writing synchronously (blocking and making the process wait until the I/O is committed to disk). Of course, a filesystem also has to preserve write order, so when it starts writing synchronously it first has to destage the cache. Hence the long pause.
The nice thing is that these are controllable options, and based on your workloads & data you can decide how you want to set them up. Let’s take a look:
$ sysctl -a | grep dirty
vm.dirty_background_ratio = 10
vm.dirty_background_bytes = 0
vm.dirty_ratio = 20
vm.dirty_bytes = 0
vm.dirty_writeback_centisecs = 500
vm.dirty_expire_centisecs = 3000vm.dirty_background_ratio is the percentage of system memory that can be filled with “dirty” pages — memory pages that still need to be written to disk — before the pdflush/flush/kdmflush background processes kick in to write it to disk. My example is 10%, so if my virtual server has 32 GB of memory that’s 3.2 GB of data that can be sitting in RAM before something is done.
vm.dirty_ratio is the absolute maximum amount of system memory that can be filled with dirty pages before everything must get committed to disk. When the system gets to this point all new I/O blocks until dirty pages have been written to disk. This is often the source of long I/O pauses, but is a safeguard against too much data being cached unsafely in memory.
vm.dirty_background_bytes and vm.dirty_bytes are another way to specify these parameters. If you set the _bytes version the _ratio version will become 0, and vice-versa.
vm.dirty_expire_centisecs is how long something can be in cache before it needs to be written. In this case it’s 30 seconds. When the pdflush/flush/kdmflush processes kick in they will check to see how old a dirty page is, and if it’s older than this value it’ll be written asynchronously to disk. Since holding a dirty page in memory is unsafe this is also a safeguard against data loss.
vm.dirty_writeback_centisecs is how often the pdflush/flush/kdmflush processes wake up and check to see if work needs to be done.
You can also see statistics on the page cache in /proc/vmstat:
$ cat /proc/vmstat | egrep "dirty|writeback"
nr_dirty 878
nr_writeback 0
nr_writeback_temp 0In my case I have 878 dirty pages waiting to be written to disk.
Approach 1: Decreasing the Cache
As with most things in the computer world, how you adjust these depends on what you’re trying to do. In many cases we have fast disk subsystems with their own big, battery-backed NVRAM caches, so keeping things in the OS page cache is risky. Let’s try to send I/O to the array in a more timely fashion and reduce the chance our local OS will, to borrow a phrase from the service industry, be “[in the weeds](http://www.urbandictionary.com/define.php?term=in the weeds).” To do this we lower vm.dirty_background_ratio and vm.dirty_ratio by adding new numbers to /etc/sysctl.conf and reloading with “sysctl –p”:
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10This is a typical approach on virtual machines, as well as Linux-based hypervisors. I wouldn’t suggest setting these parameters to zero, as some background I/O is nice to decouple application performance from short periods of higher latency on your disk array & SAN (“spikes”).
Approach 2: Increasing the Cache
There are scenarios where raising the cache dramatically has positive effects on performance. These situations are where the data contained on a Linux guest isn’t critical and can be lost, and usually where an application is writing to the same files repeatedly or in repeatable bursts. In theory, by allowing more dirty pages to exist in memory you’ll rewrite the same blocks over and over in cache, and just need to do one write every so often to the actual disk. To do this we raise the parameters:
vm.dirty_background_ratio = 50
vm.dirty_ratio = 80Sometimes folks also increase the vm.dirty_expire_centisecs parameter to allow more time in cache. Beyond the increased risk of data loss, you also run the risk of long I/O pauses if that cache gets full and needs to destage, because on large VMs there will be a lot of data in cache.
Approach 3: Both Ways
There are also scenarios where a system has to deal with infrequent, bursty traffic to slow disk (batch jobs at the top of the hour, midnight, writing to an SD card on a Raspberry Pi, etc.). In that case an approach might be to allow all that write I/O to be deposited in the cache so that the background flush operations can deal with it asynchronously over time:
vm.dirty_background_ratio = 5
vm.dirty_ratio = 80Here the background processes will start writing right away when it hits that 5% ceiling but the system won’t force synchronous I/O until it gets to 80% full. From there you just size your system RAM and vm.dirty_ratio to be able to consume all the written data. Again, there are tradeoffs with data consistency on disk, which translates into risk to data. Buy a UPS and make sure you can destage cache before the UPS runs out of power. ?
No matter the route you choose you should always be gathering hard data to support your changes and help you determine if you are improving things or making them worse. In this case you can get data from many different places, including the application itself, /proc/vmstat, /proc/meminfo, iostat, vmstat, and many of the things in /proc/sys/vm. Good luck!
Better Linux Disk Caching & Performance with vm.dirty_ratio & vm.dirty_background_ratio
性能优化:Swap调优
2015年12月05日 14:42:16tenfyguo阅读数:10598更多
个人分类: linux研究
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/tenfyguo/article/details/50185915
目标:解决大量Log写入占用大量的File Cache,内容利用不充分导致swap
基本原则:尽量使用内存,减少swap,同时,尽早flush到外存,早点释放内存给写cache使用。—特别在持续的写入操作中,此优化非常有效。
调优措施:
vm.swapiness :60 改成 10
vm.dirty_ratio:90 改成 10
vm.dirty_background_ratio:60 改成 5
vm.dirty_expire_centisecs:3000改成500
vm.vfs_cache_pressure:100 改成 500
下面重点解释一下各个配置的含义:
一,vm.swappiness优化:
swappiness的值的大小对如何使用swap分区是有着很大的联系的。swappiness=0的时候表示最大限度使用物理内存,然后才是 swap空间,swappiness=100的时候表示积极的使用swap分区,并且把内存上的数据及时的搬运到swap空间里面。linux的基本默认设置为60,具体如下:
cat /proc/sys/vm/swappiness
60
也就是说,你的内存在使用到100-60=40%的时候,就开始出现有交换分区的使用。大家知道,内存的速度会比磁盘快很多,这样子会加大系统io,同时造的成大量页的换进换出,严重影响系统的性能,所以我们在操作系统层面,要尽可能使用内存,对该参数进行调整。
临时调整的方法如下,我们调成10:
sysctl vm.swappiness=10
vm.swappiness = 10
cat /proc/sys/vm/swappiness
10
这只是临时调整的方法,重启后会回到默认设置的
要想永久调整的话,需要将在/etc/sysctl.conf修改,加上:
cat /etc/sysctl.conf
vm.swappiness=10
二,vm.dirty_ratio: 同步刷脏页,会阻塞应用程序
这个参数控制文件系统的同步写写缓冲区的大小,单位是百分比,表示当写缓冲使用到系统内存多少的时候(即指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),),开始向磁盘写出数据,即系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存),在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能。但是,当你需要持续、恒定的写入场合时,应该降低其数值,一般启动上缺省是 10。
三,vm.dirty_background_ratio:异步刷脏页,不会阻塞应用程序
这个参数控制文件系统的后台进程,在何时刷新磁盘。单位是百分比,表示系统内存的百分比,意思是当写缓冲使用到系统内存多少的时候,就会触发pdflush/flush/kdmflush等后台回写进程运行,将一定缓存的脏页异步地刷入外存。增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能。但是,当你需要持续、恒定的写入场合时,应该降低其数值,一般启动上缺省是 5。
注意:如果dirty_ratio设置比dirty_background_ratio大,可能认为dirty_ratio的触发条件不可能达到,因为每次肯定会先达到vm.dirty_background_ratio的条件,然而,确实是先达到vm.dirty_background_ratio的条件然后触发flush进程进行异步的回写操作,但是这一过程中应用进程仍然可以进行写操作,如果多个应用进程写入的量大于flush进程刷出的量那自然会达到vm.dirty_ratio这个参数所设定的坎,此时操作系统会转入同步地处理脏页的过程,阻塞应用进程。
四,vm.dirty_expire_centisecs:
这个参数声明Linux内核写缓冲区里面的数据多“旧”了之后,pdflush进程就开始考虑写到磁盘中去。单位是 1/100秒。缺省是 3000,也就是 30 秒的数据就算旧了,将会刷新磁盘。对于特别重载的写操作来说,这个值适当缩小也是好的,但也不能缩小太多,因为缩小太多也会导致IO提高太快。建议设置为 1500,也就是15秒算旧。当然,如果你的系统内存比较大,并且写入模式是间歇式的,并且每次写入的数据不大(比如几十M),那么这个值还是大些的好。
五,Vm.dirty_writeback_centisecs:
这个参数控制内核的脏数据刷新进程pdflush的运行间隔。单位是 1/100 秒。缺省数值是500,也就是 5 秒。如果你的系统是持续地写入动作,那么实际上还是降低这个数值比较好,这样可以把尖峰的写操作削平成多次写操作。设置方法如下:
echo "200" > /proc/sys/vm/dirty_writeback_centisecs
如果你的系统是短期地尖峰式的写操作,并且写入数据不大(几十M/次)且内存有比较多富裕,那么应该增大此数值:
六,Vm.vfs_cache_pressure:
增大这个参数设置了虚拟内存回收directory和inode缓冲的倾向,这个值越大。越易回收
该文件表示内核回收用于directory和inode cache内存的倾向;缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比;降低该值低于100,将导致内核倾向于保留directory和inode cache;增加该值超过100,将导致内核倾向于回收directory和inode cache。
This variable controls the tendency of the kernel to reclaim thememory which is used for caching of VFS caches, versus pagecache and swap.Increasing this value increases the rate at which VFS caches are reclaimed.Itis difficult to know when this should be changed, other than byexperimentation. The slabtop command (part of the package procps) shows topmemory objects used by the kernel. The vfs caches are the "dentry"and the "*_inode_cache" objects. If these are consuming a largeamount of memory in relation to pagecache, it may be worth trying to increasepressure. Could also help to reduce swapping. The default value is 100.